
Conversational Analytics on SQL Server with Azure OpenAI
For most organizations, marketing analysts rely on dashboards, spreadsheets, or SQL-savvy colleagues to access insights about campaign performance, customer segmentation, or regional trends. But what if your internal tools could let them simply ask a question in plain english like “How many new customers signed up last month from California?” and get an accurate, live answer in seconds?
That’s the goal of conversational analytics: enabling business teams to work directly with raw data using natural language, without writing SQL or waiting on data teams.
In this blog post, I’ll walk you through how to build a conversational analytics backend using Azure OpenAI, SQL Server, and FastAPI. This solution is designed for engineering teams that want to embed natural language querying into existing internal tools.
- The architecture follows DevOps best practices
- Version-controlled code in GitHub
- Infrastructure as code (IaC) using Terraform
- Secret management using Azure Key Vault
- Containerized backend deployed via Azure Container Apps
Table of Contents
- Conversational Analytics
- Architecture Overview
- Database Overview
- Step-by-Step Implementation
- Harden for Production
- Conclusion
Prerequisites
Before getting started, make sure you have the following tools and access in place:
- Microsoft Azure Subscription: In which to provision the cloud infrastructure (SQL Server, OpenAI, Key Vault, ACR, and Container Apps).
- Terraform: For defining and deploying Azure infrastructure as code.
- Python: For building the FastAPI application backend.
- Docker: For containerizing the FastAPI app before deploying it to Azure Container Apps.
Conversational Analytics
In the context of the solution we are going to build, conversational analytics means enabling users (e.g., business analysts, marketing teams) to interact directly with live data in Azure SQL just by typing questions into a simple text box or REST client. Users simply ask questions like:
“How many customers placed orders last month?” “What was our top selling product in California?”
This bridges the gap between technical data systems and non technical users, removing the need for SQL expertise or waiting on data teams. In short, conversational analytics makes data analysis as simple as having a conversation, while still leveraging the power and structure of data systems like SQL Server.
Architecture Overview
At a high level, our solution enables business users (e.g. marketing analysts) to query live data using natural language via a secure REST API:
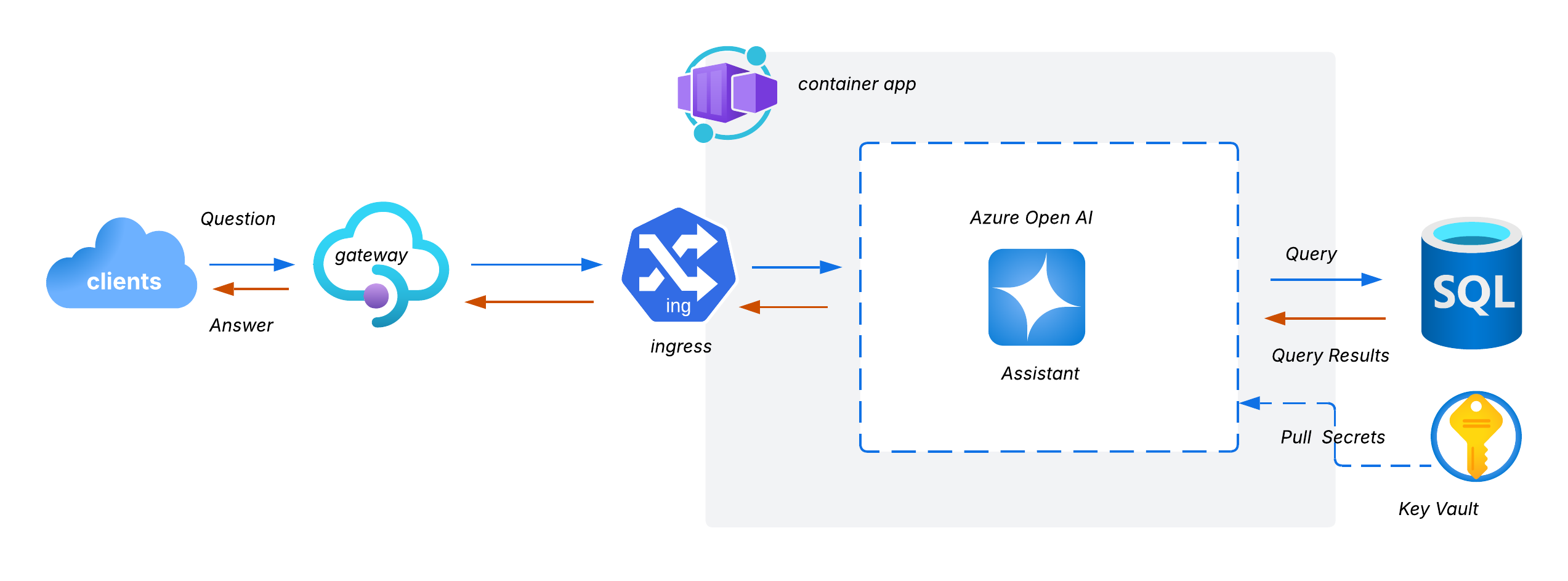
User Interaction:
- Users send natural language questions (e.g. “How many customers placed orders last month?”) to the /chat endpoint exposed by the FastAPI service.
Backend Logic
- The incoming question is passed to an Azure OpenAI powered GPT-4 assistant.
- The assistant uses a schema aware system prompt to translate the natural language into a valid SQL query.
- The query is executed against the Azure SQL Server (which hosts the AdventureWorks database).
- Results are returned, along with: the original SQL query, the structured data result (in JSON) and a plain English explanation of what the query did. The /chat endpoint responds with all 3 elements: query, results, and explanation. This empowers users to learn SQL over time while getting fast answers.
Database Overview
For this demonstration, we will connect our assistant to the AdventureWorksLT sample database, a widely-used dataset provided by Microsoft to simulate real world retail and sales operations. This Lightweight Sales schema (SalesLT) includes the following tables:
- Customer: customer info like name, contact, company
- Address: street, city, state, ZIP
- CustomerAddress: mapping between customers and addresses
- SalesOrderHeader, SalesOrderDetail: orders and their items
- Product: product catalog
- ProductCategory: category hierarchy
This schema is realistic enough to mirror many internal business use cases making it ideal for prototyping AI driven analytics on real looking data without exposing sensitive production systems.
- Schema Prompting
To make our solution reliable and avoid the risk of guesses and hallucination, the LLM must understand:
- What tables exist
- How they relate to each other
- Which fields are available
- What to filter on
To achieve this, we will use schema based prompting to help the GPT-4 model generate accurate SQL queries. This means we explicitly provide the model with a structured description of the database including table names, column names, and their relationships along with the user’s natural language question. It looks something like:
SCHEMA = """
Tables:
- Customer(CustomerID, FirstName, LastName, EmailAddress)
- Address(AddressID, StateProvince, City, PostalCode)
- CustomerAddress(CustomerID, AddressID)
- SalesOrderHeader(SalesOrderID, CustomerID, OrderDate, TotalDue)
- SalesOrderDetail(SalesOrderID, ProductID, OrderQty, LineTotal)
- Product(ProductID, Name, ProductCategoryID)
- ProductCategory(ProductCategoryID, Name)
Relationships:
- Customer joins CustomerAddress on CustomerID
- CustomerAddress joins Address on AddressID
- Customer joins SalesOrderHeader on CustomerID
- SalesOrderHeader joins SalesOrderDetail on SalesOrderID
- SalesOrderDetail joins Product on ProductID
- Product joins ProductCategory on ProductCategoryID
"""This ensures our assistant:
- Understands how the database is structured, what tables are available, and how they relate.
- Generates valid SQL queries that follow the correct join paths and column references.
- Users don’t need to know SQL or how the schema is designed, they just ask questions in plain English.
Project Setup
With that out of the way, it’s time to walk through deploying and running the solution in your own Azure environment. I will guide you through cloning the repo, provisioning cloud infrastructure with Terraform, and deploying the containerized application to Azure Container Apps. Let’s get started
To get started quickly, clone the project repository which contains all the code and Terraform configuration needed to deploy the full solution.
git clone https://github.com/musana-engineering/sqlCopilot.git
cd sqlCopilotThe repository uses the following structure:
sqlCopilot
├── README.md # Project overview
├── app/ # FastAPI application with Azure OpenAI integration
│ ├── main.py # Entrypoint: exposes /chat API
│ ├── assistant.py # Handles GPT-4 prompt generation
│ ├── db.py # Azure SQL DB connection
│ ├── secrets.py # Azure Key Vault integration
│ ├── requirements.txt # Python dependencies
│ ├── Dockerfile # Container image definition
├── infra/ # Terraform configurations
│ ├── database/ # Azure SQL Server and AdventureWorks DB
│ ├── openai/ # Azure OpenAI and Key Vault setupInfrastructure Setup
Before you run any Terraform commands, make sure the following are set up:
- An Azure subscription to deploy Azure SQL and OpenAI resources.
- A service principal with Contributor access to the target subscription.
- Terraform installed on your machine.
Navigate to the infra/ folder
cd infra
terraform init && terraform applyTerraform will create:
- Azure SQL Server + AdventureWorks schema
- Azure OpenAI deployment (GPT-4)
- Azure Key Vault with secret entries
- Networking and firewall configuration
OpenAI Setup
Once the infrastructure is up, update your app to pull secrets (like the database connection string and OpenAI credentials) directly from Azure Key Vault. This is handled in secrets.py, which authenticates using Azure’s DefaultCredential chain and retrieves secrets securely.
from azure.identity import DefaultAzureCredential
from azure.keyvault.secrets import SecretClient
key_vault_name = "kv-0fe8b4"
key_vault_uri = f"https://{key_vault_name}.vault.azure.net/"
database_connectionstring_secret = "sql-server-admin-password"
open_api_key_secret = "openai-api-key"
credential = DefaultAzureCredential()
key_vault_client = SecretClient(vault_url=key_vault_uri, credential=credential)
db_connection_string = key_vault_client.get_secret(database_connectionstring_secret).value
open_api_key = key_vault_client.get_secret(open_api_key_secret).valueReplace sql-connection-string and openai-api-key with the actual secret names defined in your Azure Key Vault. These are provisioned automatically by Terraform in the infra/openai and infra/database modules.
-
Project Packaging
-
Project Deployment