
The DevOps Playbook for Production Ready AI – Part 1
Our camera rolls are digital graveyards of forgotten photos. While taking a picture is effortless, creating one worthy of sharing requires a keen eye and thoughtful editing. Similarly, in AI, the initial thrill of a working prototype is like that quick snapshot. But the journey to production where it must perform reliably for users is where the real work begins.
Production is less about ideation and more about engineering an AI serving platform that is secure, scalable, resilient, observable, cost-efficient, and maintainable. This is not trivial work.
You can’t just filter your way to a stable production system. A prototype built on vibes will collapse under real world load
This is precisely where a mature DevOps and Platform Engineering culture becomes a powerful advantage. These teams bring the battle tested disciplines of modern software delivery such as automation, CI/CD, observability, and infrastructure-as-code (IaC) into AI initiatives. By applying these practices, they help organizations move beyond endless experimentation and deliver production grade deployments that generate measurable ROI
In this multi-part blog series, I’ll show you what that effort looks like through a practical, end-to-end deployement of a Predictive AI project on Microsoft Azure starting from concept all the way to production.
Table of Contents
Prerequisites
This is a complex technical implementation so before we dive in I assume you have a strong understanding and hands-on experience with the following
- Machine Learning concepts including model training, evaluation, and deployment.
- DevOps concepts like CI/CD pipelines and version control
- Platform Engineering concepts and principles
- Python programming and the Azure ML SDK for Python
- Snowflake data platform.
- Azure Kubernetes
- Infrastructure as code using Terraform
Ensure that Argo Events and Argo Workflows are installed on your Kubernetes cluster. Argo Events will handle event-driven triggers for the pipelines, while Argo Workflows will be used to author and execute them
Introduction
GloboRealty is a fictitious real estate company specializing in residential properties across urban, suburban, and waterfront markets. They are looking to build machine learning models that can estimate the value of a property based on various feature such as location, square footage, number of bedrooms and year built.
To bring this vision to life, their platform engineering team is leveraging Azure Machine Learning (AML) with strong DevOps and MLOps practices. Their workflow starts with data stored in Snowflake, securely connected to their AML workspace. Pipelines ingest this data into Azure Blob Storage as raw datasets, which are then preprocessed into curated, training ready datasets. From there, models are trained, evaluated, and deployed through automated CI/CD pipelines ensuring every version is traceable, tested, and monitored in production.
In Part 1, we’ll focus on two key steps:
- Infrastructure Setup: Provision the Azure Machine Learning (AML) workspace and configure supporting services such as Blob Storage, Key Vault, and Managed Identity.
- Data Acquisition: Establish a secure connection between the AML workspace and Snowflake and ingest historical data into Azure Blob Storage as a raw (bronze) dataset, ready for preprocessing in Part 2.
Infrastructure Setup
Before we can begin acquiring and preparing the raw data, we need a secure and reliable infrastructure foundation in Azure. We’ve chosen Azure Machine Learning (AML) as it provides experiment tracking, dataset management, and integration with pipelines for automation. This foundation is illustrated in the diagram below:
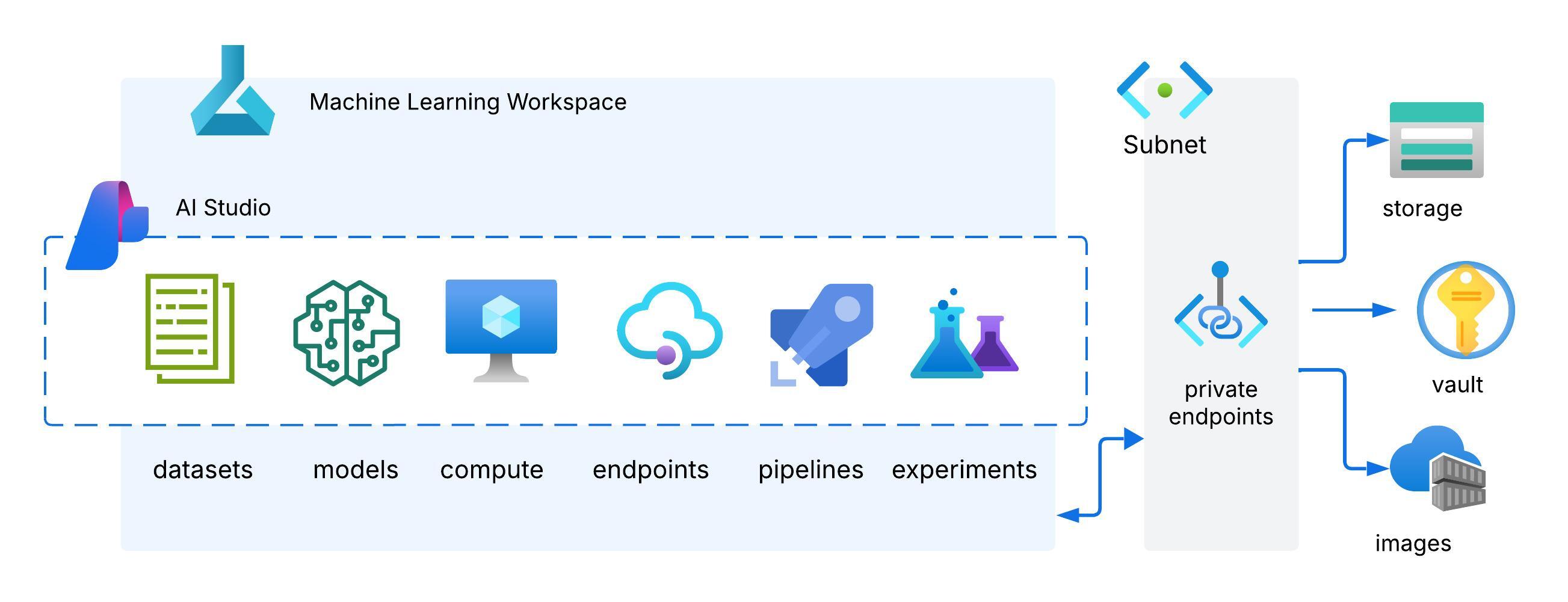
Alongside the workspace, several supporting Azure services are provisioned:
- Azure Storage Account: For storing and separation of datasets at different stages.
- Azure Key Vault: For storing secrets, connection strings and other sensitive information
- Managed Identity: For secure role-based access to resources like Storage and Key Vault without embedding credentials.
- Azure Container Registry (ACR): For hosting custom Docker images with specific dependencies for training and inference
To make the setup repeatable and version-controlled, we define all resources as infrastructure as code using Terraform.
Follow the steps below to provision the environment.
# First, clone the project repository that contains the Terraform files
https://github.com/musana-engineering/globorealty.git
# Authenticate with Azure
export ARM_CLIENT_ID="your_azure_sp_client_id"
export ARM_CLIENT_SECRET="your_azure_sp_client_secret"
export ARM_TENANT_ID="your_azure_tenant_id"
export ARM_SUBSCRIPTION_ID="your_azure_subscription_id"
# Initialize Terraform and Review the plan
terraform init && terraform plan
# Apply the configuration
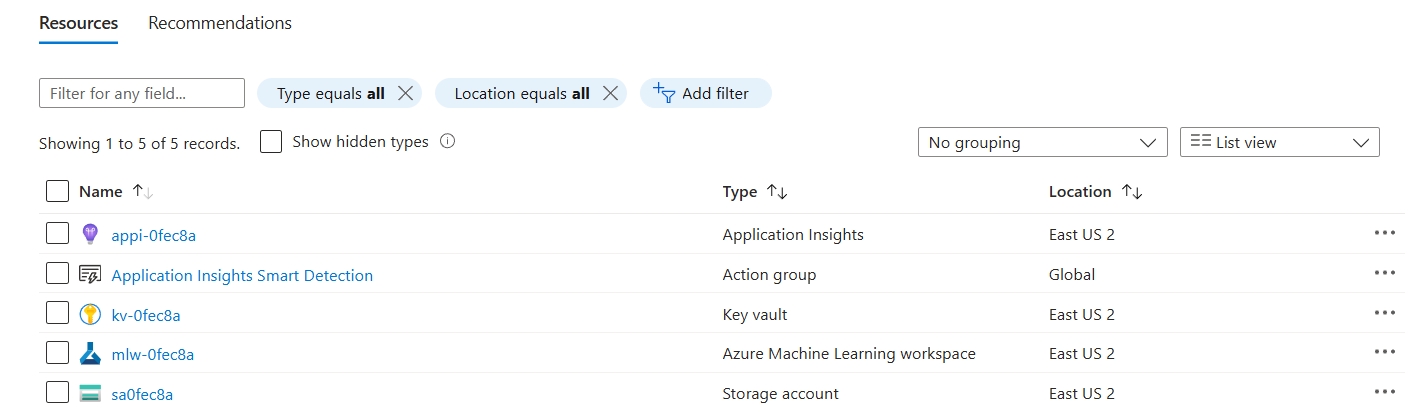
terraform applyOnce terraform deployment finishes, log in to the Azure Portal and confirm:
- The AML Workspace is active.
- Linked resources (Storage, Key Vault, ACR, Managed Identity) are available.
- You can access the workspace in Azure AI Studio.
Security Considerations
- VNET integration for the AML Workspace to keep workloads isolated.
- Private Endpoints for Storage and Key Vault to keep traffic on the Microsoft backbone.
- Managed Identity handles RBAC securely between AML and dependent services.
- Key Vault stores secrets and sensitive credentials, retrieved securely on demand.
At this point, we have a secure foundation for our AI platform. Next, we’ll move to data acquisition, where we’ll connect to Snowflake and ingest house price data into Blob Storage as the raw/bronze dataset.
Data Acquistion
With the Azure ML infrastructure in place, the next step is to bring data into the Azure environment. GloboRealty’s historical house price dataset resides in Snowflake, so we need to establish a secure pipeline that moves this data into Azure Machine Learning for further processing. The flow is illustrated in the diagram below:
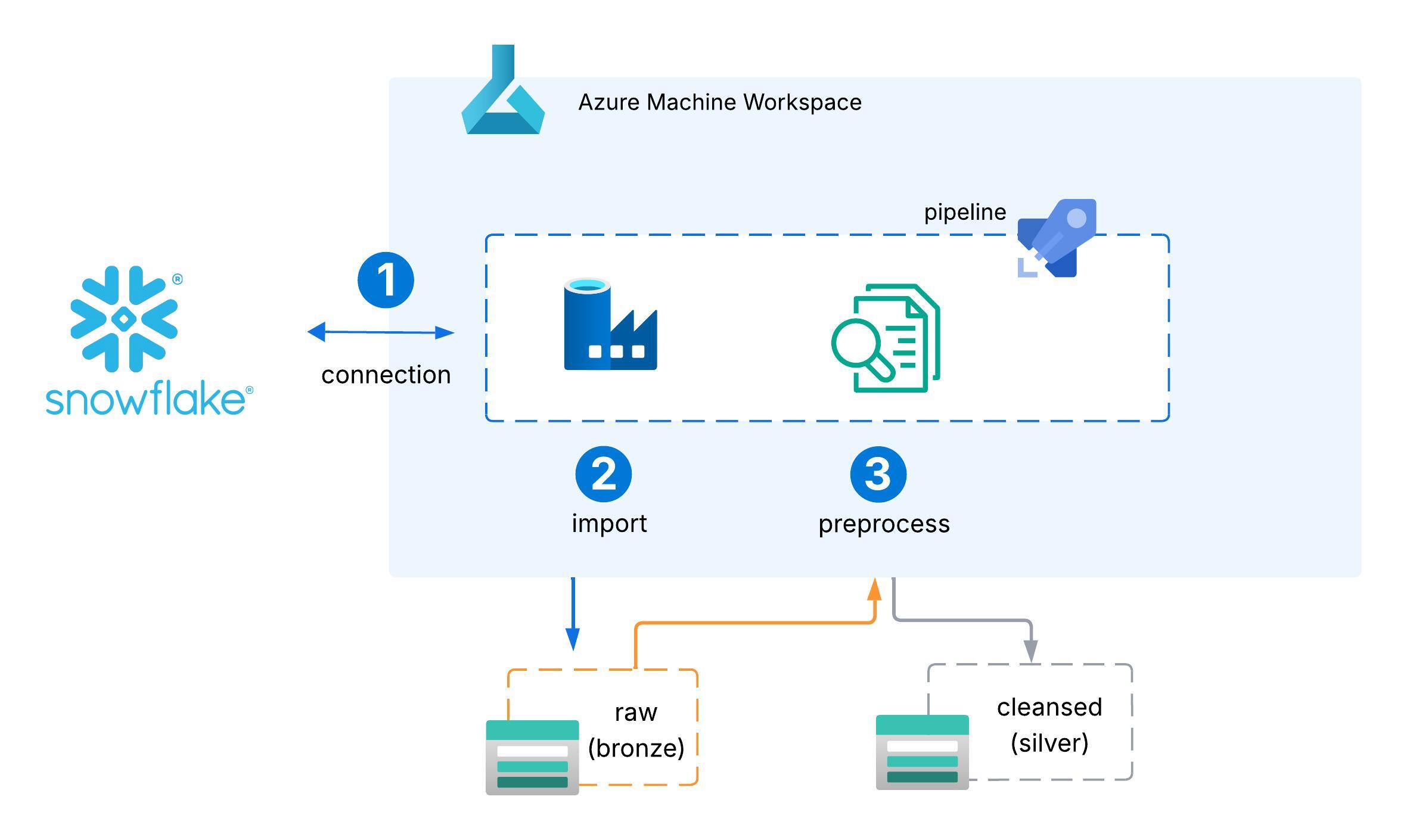
To achieve this, we’ll use the Azure ML SDK for Python to author scripts that automate each step of the process. Specifically, we’ll complete the following tasks:
- Create a data connection to store the credentials needed to securely connect to the Snowflake account, which is the source of the raw dataset.
from azure.ai.ml import MLClient
from azure.ai.ml.entities import WorkspaceConnection
from azure.identity import DefaultAzureCredential
from dotenv import load_dotenv
load_dotenv()
subscription_id = os.getenv("SUBSCRIPTION_ID")
resource_group_name = os.getenv("RESOURCE_GROUP_NAME")
workspace_name = os.getenv("WORKSPACE_NAME")
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id=subscription_id,
resource_group_name=resource_group_name,
workspace_name=workspace_name
)from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import WorkspaceConnection
from azure.ai.ml.entities import UsernamePasswordConfiguration
from dotenv import load_dotenv
import os, json
from create_client import ml_client, workspace_name
load_dotenv()
import urllib.parse
snowflake_account = os.getenv("SNOWFLAKE_ACCOUNT")
snowflake_database = os.getenv("SNOWFLAKE_DATABASE")
snowflake_warehouse = os.getenv("SNOWFLAKE_WAREHOUSE")
snowflake_role = os.getenv("SNOWFLAKE_ROLE")
snowflake_db_username = os.getenv("SNOWFLAKEDB_USERNAME")
snowflake_db_password = os.getenv("SNOWFLAKEDB_PASSWORD")
snowflake_connection_string = f"jdbc:snowflake://{snowflake_account}.snowflakecomputing.com/?db={snowflake_database}&warehouse={snowflake_warehouse}&role={snowflake_role}"
connection_name = "Snowflake"
try:
ml_client.connections.get(name=connection_name)
print(f"Connection '{connection_name}' already exists")
except:
wps_connection = WorkspaceConnection(
name=connection_name,
type="snowflake",
target=snowflake_connection_string,
credentials=UsernamePasswordConfiguration(username=snowflake_db_username, password=snowflake_db_password)
)
ml_client.connections.create_or_update(workspace_connection=wps_connection)
print(f"Workspace connection '{connection_name}' created.")
verify_connection_creation = ml_client.connections.list(connection_type="snowflake")
print("\nConnection details:")
for connection in verify_connection_creation:
print(json.dumps(connection._to_dict(), indent=4))
Note: creating a Snowflake connection doesn’t pull data by itself. The DataImport call we make to create a data asset is what executes the query against Snowflake and writes the results to Blob. The finished files are then registered as a reusable, versioned data asset.
- Create a datastore to define the link to the Azure Storage account, the destination where raw data from Snowflake will be ingested
from azure.ai.ml.data_transfer import Database
from azure.ai.ml.entities import DataImport, Data, DataAsset, Datastore
from azure.ai.ml.entities import AzureBlobDatastore, AccountKeyConfiguration
from dotenv import load_dotenv
import os, json
from azure.core.exceptions import ResourceNotFoundError
from create_client import ml_client, workspace_name
raw_datastore_name = "rawdata"
storage_account_name = os.getenv("STORAGE_ACCOUNT_NAME")
storage_account_key = os.getenv("STORAGE_ACCOUNT_ACCESS_KEY")
# Create datastore for raw data
create_datastore = AzureBlobDatastore(
name=raw_datastore_name,
account_name=storage_account_name,
container_name=raw_datastore_name,
credentials=AccountKeyConfiguration(account_key=storage_account_key),
)
try:
ml_client.datastores.get(name=raw_datastore_name)
print(f"Datastore '{raw_datastore_name}' already exists")
except ResourceNotFoundError:
ml_client.datastores.create_or_update(create_datastore)
print(f"Datastore '{raw_datastore_name}' created")
# Return list of datastore to verify the new datastore exists
verify_datastore_creation = ml_client.datastores.list(include_secrets=False)
print("\nDatastore details:")
for datastore in verify_datastore_creation:
print(json.dumps(datastore._to_dict(), indent=4))
- Create a data asset to register a reference to the ingested raw dataset so it can be tracked, versioned, and reused across pipelines.
This step uses the Azure ML DataImport API to run the import job from Snowflake into Blob Storage and register the resulting raw dataset as a versioned data asset.
from azure.ai.ml.data_transfer import Database
from azure.ai.ml.entities import DataImport, Data, DataAsset, Datastore
from dotenv import load_dotenv
import os, json, mltable, pandas
from azure.core.exceptions import ResourceNotFoundError
from create_client import ml_client, workspace_name
from create_connection import connection_name
from create_datastore import raw_datastore_name
dataset_name = "raw_house_data"
try:
ml_client.data.get(name=dataset_name, version="1")
print(f"Dataset '{dataset_name}' already exists")
except ResourceNotFoundError:
print(f"Registering '{dataset_name}' dataset")
data_import = DataImport(
name=dataset_name,
source=Database(
connection=connection_name,
query=f"SELECT * FROM GLOBOREALTY.REAL_ESTATE.RAW"
),
path=f"azureml://datastores/{raw_datastore_name}/paths/{dataset_name}",
version="1"
)
ml_client.data.import_data(data_import=data_import)
verify_dataset_creation = ml_client.datastores.list(include_secrets=False)
print("\nDatastore details:")
for dataset in verify_dataset_creation:
print(json.dumps(dataset._to_dict(), indent=4))
- Verify data import to confirm that the raw data has been successfully ingested into Blob Storage and is available for preprocessing in the next stage.
import pandas, mltable
from create_connection import ml_client
from create_dataset import dataset_name
from create_connection import ml_client
data_asset = ml_client.data.get(dataset_name, version="1")
tbl = mltable.load(data_asset.path)
df = tbl.to_pandas_dataframe()
df
print(df.head(10))
print(df.describe())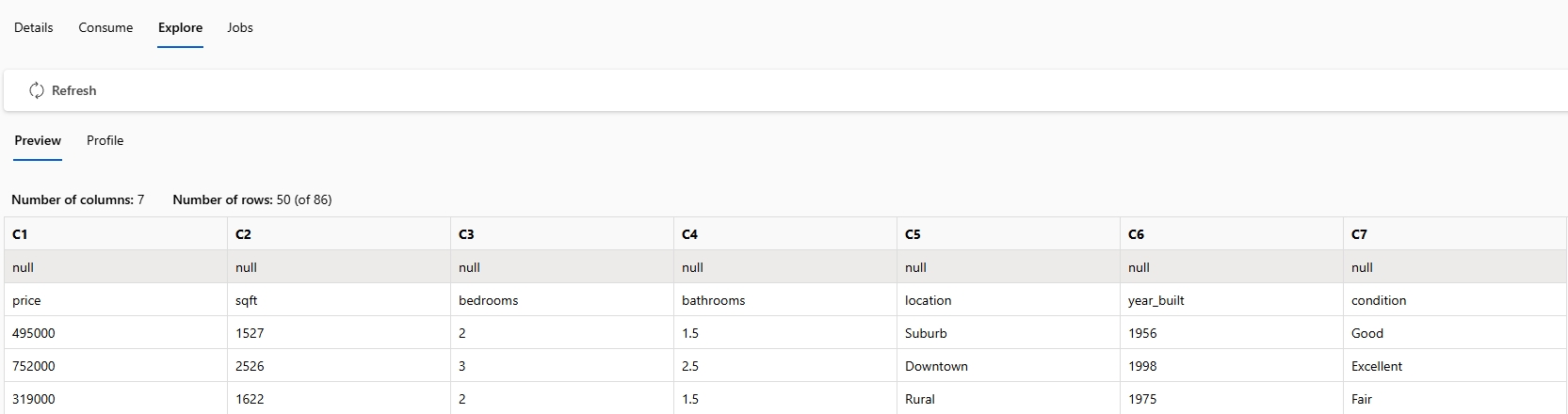
Pipeline Setup
To make everything we’ve done so far repeatable end-to-end, we need to orchestrate everything with Argo Workflows running on AKS. For a deeper introduction to Argo Workflows, see my series on Platform Engineering with Kubernetes here Part 1 and Part 1
To keep things modular, maintainable, and aligned with team responsibilities, we’ll split our automation into two distinct pipelines. This separation allows platform engineers to focus on infrastructure while data and ML engineers manage data ingestion and AML connections. It also means infrastructure changes don’t slow down the more frequent data refresh cycles.
We’ll define and submit two pipelines, each with a clear responsibility:
- Infrastructure Pipeline:
Handles the creation and ongoing maintenance of Azure resources such as the AML workspace, Storage Account, Key Vault, and Container Registry.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: infra-0fec8a
namespace: argo
spec:
entrypoint: update
podGC:
strategy: OnWorkflowSuccess
arguments:
parameters:
- name: docker-image
value: musanaengineering/platformtools:terraform:1.0.0
- name: infrastructure-repository
value: https://github.com/musana-engineering/globorealty.git
templates:
- name: plan
inputs:
artifacts:
- name: terraform
path: /home/terraform
git:
repo: {{ workflow.parameters.infrastructure-repository ' }}
depth: 1
volumes:
- name: pipeline-secrets
secret:
secretName: infra-0fec8a
script:
imagePullPolicy: "Always"
image: {{ workflow.parameters.docker-image ' }}
command: [/bin/bash]
source: |
export ARM_CLIENT_ID="your_azure_sp_client_id"
export ARM_CLIENT_SECRET="$CLIENT_SECRET"
export ARM_TENANT_ID="your_azure_tenant_id"
export ARM_SUBSCRIPTION_ID="your_azure_subscription_id"
cd /home/terraform/globorealty/infrastructure
terraform init -input=false
terraform plan -parallelism=2 -input=false -no-color -out=/home/terraform/artifacts/Infrastructure.tfplan /home/argo >> /tmp/terraform-change.log
env:
- name: CLIENT_SECRET
valueFrom:
secretKeyRef:
name: pipeline-secrets
key: CLIENT_SECRET
outputs:
artifacts:
- name: terraform-plan
path: /home/terraform/home/terraform/artifacts/
archive:
none: {}
- name: terraform-log
path: /tmp/terraform-change.log
archive:
none: {}
- name: apply
inputs:
artifacts:
- name: terraform-plan
path: /home/terraform
volumes:
- name: pipeline-secrets
secret:
secretName: infra-0fec8a
script:
imagePullPolicy: "Always"
image: {{ workflow.parameters.docker-image ' }}
command: [/bin/bash]
source: |
export ARM_CLIENT_ID="your_azure_sp_client_id"
export ARM_CLIENT_SECRET="$CLIENT_SECRET"
export ARM_TENANT_ID="your_azure_tenant_id"
export ARM_SUBSCRIPTION_ID="your_azure_subscription_id"
/bin/terraform apply -input=false -parallelism=2 -no-color /home/terraform/artifacts/Infrastructure.tfplan
env:
- name: CLIENT_SECRET
valueFrom:
secretKeyRef:
name: pipeline-secrets
key: CLIENT_SECRET
- name: approve
suspend: {}
- name: update
dag:
tasks:
- name: plan
template: plan
- name: approve
dependencies: [plan]
template: approve
- name: apply
template: apply
dependencies: [plan, approve]
arguments:
artifacts:
- name: terraform-plan
from: {{ tasks.plan.outputs.artifacts.terraform ' }} - Data Pipeline:
Establishes and manages AML connections (datastores and data assets) and orchestrates the ingestion of raw data from Snowflake into Azure Blob Storage.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: data-0fec8a
namespace: argo
spec:
entrypoint: pipeline
podGC:
strategy: OnWorkflowSuccess
arguments:
parameters:
- name: docker-image
value: musanaengineering/platformtools:python:1.0.0
- name: data-repository
value: https://github.com/musana-engineering/globorealty.git
templates:
- name: create-connection
inputs:
artifacts:
- name: scripts
path: /home/scripts
git:
repo: {{ workflow.parameters.data-repository ' }}
depth: 1
volumes:
- name: pipeline-secrets
secret:
secretName: data-0fec8a
script:
imagePullPolicy: "Always"
image: {{ workflow.parameters.docker-image ' }}
command: [/bin/bash]
source: |
export SUBSCRIPTION_ID=my_azure_ml_subscription_id
export RESOURCE_GROUP_NAME=my_azure_ml_subscription_id
export WORKSPACE_NAME=my_azure_ml_workspace_name
export SNOWFLAKE_ACCOUNT=my_snowflake_account_name
export SNOWFLAKEDB_USERNAME=my_snowflake_db_username
export SNOWFLAKEDB_PASSWORD=$SNOWFLAKEDB_PASSWORD
export SNOWFLAKE_DATABASE=my_snowflake_database
export SNOWFLAKE_WAREHOUSE=my_snowflake_warehouse
export SNOWFLAKE_ROLE=my_snowflake_role
cd /home/scripts/globorealty/scripts
python create_connection.py
env:
- name: SNOWFLAKEDB_PASSWORD
valueFrom:
secretKeyRef:
name: pipeline-secrets
key: SNOWFLAKEDB_PASSWORD
- name: create-datastore
inputs:
artifacts:
- name: scripts-plan
path: /home/scripts
volumes:
- name: pipeline-secrets
secret:
secretName: data-0fec8a
script:
imagePullPolicy: "Always"
image: {{ workflow.parameters.docker-image ' }}
command: [/bin/bash]
source: |
export STORAGE_ACCOUNT_NAME=my_azure_ml_storage_account_name
export STORAGE_ACCOUNT_ACCESS_KEY=$STORAGE_ACCOUNT_ACCESS_KEY
cd /home/scripts/globorealty/scripts
python create_datastore.py
env:
- name: STORAGE_ACCOUNT_ACCESS_KEY
valueFrom:
secretKeyRef:
name: pipeline-secrets
key: STORAGE_ACCOUNT_ACCESS_KEY
- name: create-dataset
inputs:
artifacts:
- name: scripts-plan
path: /home/scripts
volumes:
- name: pipeline-secrets
secret:
secretName: data-0fec8a
script:
imagePullPolicy: "Always"
image: {{ workflow.parameters.docker-image ' }}
command: [/bin/bash]
source: |
cd /home/scripts/globorealty/scripts
python create_dataset.py
- name: preview-data
inputs:
artifacts:
- name: scripts-plan
path: /home/scripts
volumes:
- name: pipeline-secrets
secret:
secretName: data-0fec8a
script:
imagePullPolicy: "Always"
image: {{ workflow.parameters.docker-image ' }}
command: [/bin/bash]
source: |
cd /home/scripts/globorealty/scripts
python create_dataframe.py
- name: pipeline
dag:
tasks:
- name: create-connection
template: create-connection
- name: create-datastore
template: create-datastore
dependencies: [create-connection]
- name: create-dataset
template: create-dataset
dependencies: [create-connection, create-datastore]
- name: preview-data
template: preview-data
dependencies: [create-connection, create-datastore, create-dataset]Pipeline Security Considerations
- Pipelines run on private AKS cluster keeping all operations private.
- Uses Azure Workload Identity for the Terraform AzureRM provider
- Enforce least-privilege RBAC for the workflow’s service account
- Sources secrets from Azure Key Vault via External Secrets Operator
- Writes Terraform outputs that are sensitive directly to Key Vault
- Pipelines executes using a hardened, internally maintained image.
Summary
In this first part, we’ve laid the foundation for production ready AI on Azure. We provisioned an Azure Machine Learning workspace as our core infrastructure along with supporting services like Blob Storage, Key Vault and Container Registry
On top of that foundation, we established a secure pipeline from Snowflake into Azure, successfully ingesting GloboRealty’s house price dataset into Blob Storage as the raw/bronze layer. This ensures GloboRealty now has a traceable, governed, and production aligned environment where data can flow securely from source systems into Azure ML.
In Part 2, we’ll shift focus to data preprocessing. Specifically, we will:
- Clean and transform the raw dataset into a curated silver dataset.
- Create and register a training ready data asset inside Azure ML.
- Provision and configure Azure ML Compute clusters, which will serve as the backbone for model training and evaluation.
By the end of Part 2, we will be ready to launch our first model training experiments on Azure ML using clean, curated data.
If you found this article useful, please share it with your team, network, or community. And don’t forget to check back soon for Part 2.